AI视频领域又又一次升级了!只需要一张图片和一段音频就能生成清晰度为4K分辨率并且时长能有1小时的视频吗?
像现在市面上的AI视频工具生成时间基本上都是按分钟来“计算”的,清晰度也就基本在1080P左右。
国产之光来了,复旦大学与百度联合开发了Hallo2,是目前为止首个实现长达一小时、4K 分辨率的音频驱动人像动画生成模型。
对比之前的版本的Hallo升级迭代了不止一星半点,用过Hallo第一版本的小伙伴应该都有印象,分辨率是512,视频生成时长是分钟来算的。
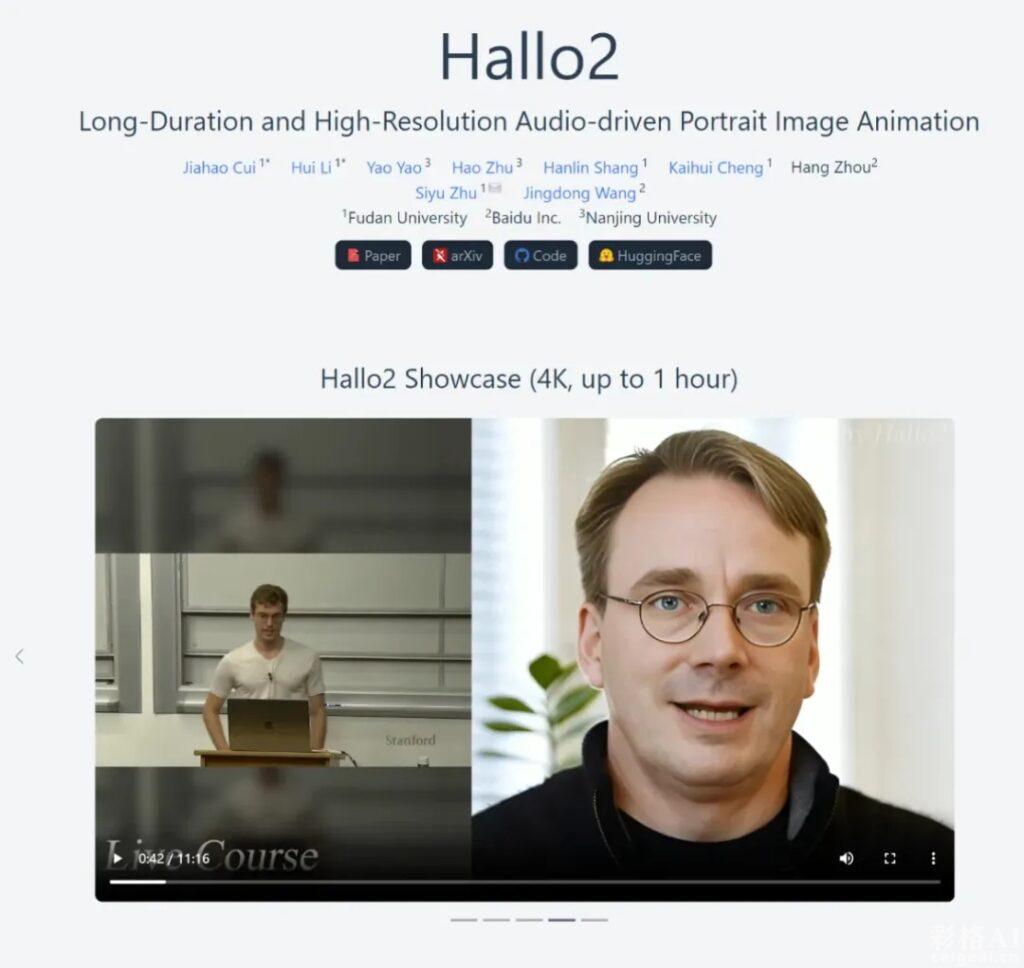
在大方向没有变的情况下,Hallo2还是音频驱动人像图像动画技术,它具备将音频转化为长达1小时、分辨率飙升至4K的生动人像视频的能力。并且操作及其简单,只需要1张照片和一段音频,属于你自己独一无二的数字人视频就制作好了
这款工具推出之后,估计各大自媒体平台会涌现很多类型的数字人,来替代自己来实现商业变现。
Hallo2为了显著提升长时间视频在视觉上的连贯性和一致性,Hallo2创新性地融入了数据增强策略,诸如patch-drop技术与高斯噪声的应用。这些手段极大地优化了视频质量。
Hallo2融合了向量量化生成对抗网络(VQ-VAE)与时间对齐技术的精髓,确保了即便是在高分辨率下,视频也能保持卓越的品质与无比流畅的视觉体验。
下图是展示Hallo2如何用一张参考图像和一段音频输入来生成视频的。

该技术引入了可调节的文本标签功能,允许用户精准地操控视频中人物的面部表情及头部动作,这一特性不仅极大地丰富了动画的情感表达,还显著增强了观众与视频内容之间的互动性。
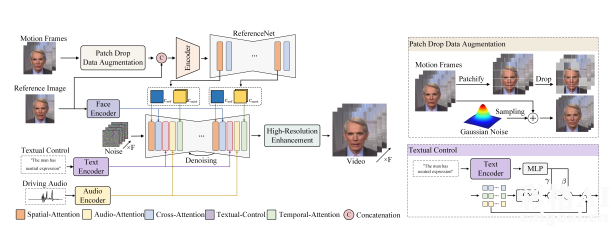
Hallo2在视觉一致性与时间连贯性上也有了很大的升级,Hallo2 通过补丁丢弃和噪声增强技术,在生成长时视频时极大程度上减少了表情抖动和外观不一致等问题。
最终生成的输出是一个高分辨率的4K视频,它与音频同步,并受这些可选表情提示的影响,确保视频在整个播放过程中保持连贯性。
看下Hallo2的官方展示视频:
以下是Hallo2的官网以及使用地址:
项目官网:
fudan-generative-vision.github.io/hallo2
GitHub:
https://github.com/fudan-generative-vision/hallo2
HuggingFace:
https://huggingface.co/fudan-generative-ai/hallo2
Hallo2的代码和预训练模型已经在GitHub和Hugging Face上开源,提供了详细的安装和使用说明。
试想一下,这款AI视频工具又高清、又持久、并且人物一致性高度还原,还能手动添加文本指挥人物的表情管理,在以后的短视频平台哪怕是短剧,岂不都是数字人,还能看到一个“真人”吗?演员行业岂不是要“凉凉”了?
适用场景非常广泛,不管是露脸还是露声音的工作,都可以让Hallo2来代替,比如演讲、教育、录播课、自媒体创作者、动画短频、甚至是电影特效都能从中受益。如果有需要制作免费数字人的小伙伴可以登录上方链接进行使用。
评论(0)